추상화를 무시하지말자..
제목은 "jpql 추상화를 무시하고 치뤄야한 대가" 인데, 의도적으로 무시한것은 절대 아니고 "무지" 했기 때문에 무시한것이다.
여하튼.. jpql을 무시한 결과로 대가를 치뤄야한 경험을 정리한 글 이다.
모든 코드는 여기에서 볼 수 있다.
https://github.com/waldreg/waldreg-api
GitHub - waldreg/waldreg-api: 대학교 동아리를 위한 그룹웨어 api server
대학교 동아리를 위한 그룹웨어 api server. Contribute to waldreg/waldreg-api development by creating an account on GitHub.
github.com
개요
우리 애플리케이션의 repository 모듈은 테스트환경에서 h2데이터베이스를 사용했고, 운영환경에서는 mysql을 사용했다.
개발중 jpql이 지원하지 않는 SQL을 Native query로 작성해야했는데, TDD 프로세스를 기반으로 개발했기 때문에, 최우선 목표는 테스트환경에서 통과하는 코드를 작성하는 것 이였고, Native query또한 h2 데이터 베이스에 맞게 작성되었다.
실제로 개발당시 무슨 데이터베이스를 사용할지 특정하지 조차 않았는데, 그 이유는 다음과 같다.
1. h2를 사용해서 모든 테스트가 통과하면 실제 운영환경에서 사용할 데이터베이스를 사용해도 모든 테스트가 통과할것이다.
2. 스프링 데이터 jpa가 제공하는 sql 방언을 사용하면, 구체적인 데이터베이스를 언제든지 바꿀 수 있다.
운영환경의 데이터베이스와 h2데이터베이스가 큰 차이가 없을것이라 생각했고 인수테스트 또한 h2 데이터베이스 위에서 수행했는데 이 오만의 결과는 후에 더 큰 폭풍으로 되돌아온다..
DBMS로 마이그레이션 작업을 마친 후, 우리는 인수 테스트를 포함한 모든 테스트가 통과함을 확인했고(물론.. h2 위에서), 메모리 데이터베이스에서 MYSQL로 성공적으로 repository 모듈을 마이그레이션 했다고 생각했다. (데이터베이스를 적용하기 전까지는 데이터를 메모리에 저장했으며 이 방식으로 버전 0.0.1에서 버전 0.4.2까지 배포를 했다.)
DB가 포함되지 않은 0.0.1에서 0.4.2버전에 이르기 까지 우리의 API는 생각한 범위 내에서 어떠한 버그도 발생하지 않았기 때문에, 우리는 확신과 함께 DB가 포함된 버전인 0.5.0을 배포했다.
긴급호출
서비스 개발의 마지막 작업이였던 DB연결까지 마치고 어느날 프론트엔드 팀원에게서 메시지가 왔다.

우리는 직감적으로 DB가 문제인것을 알아차렸는데, DBMS가 연결되기 직전 버전인 0.4.2까지는 모든게 잘 동작했기 때문이다.
실제로 문제상황을 똑같이 재현해봤고 다음과 같은 문제점을 확인할 수 있었다.
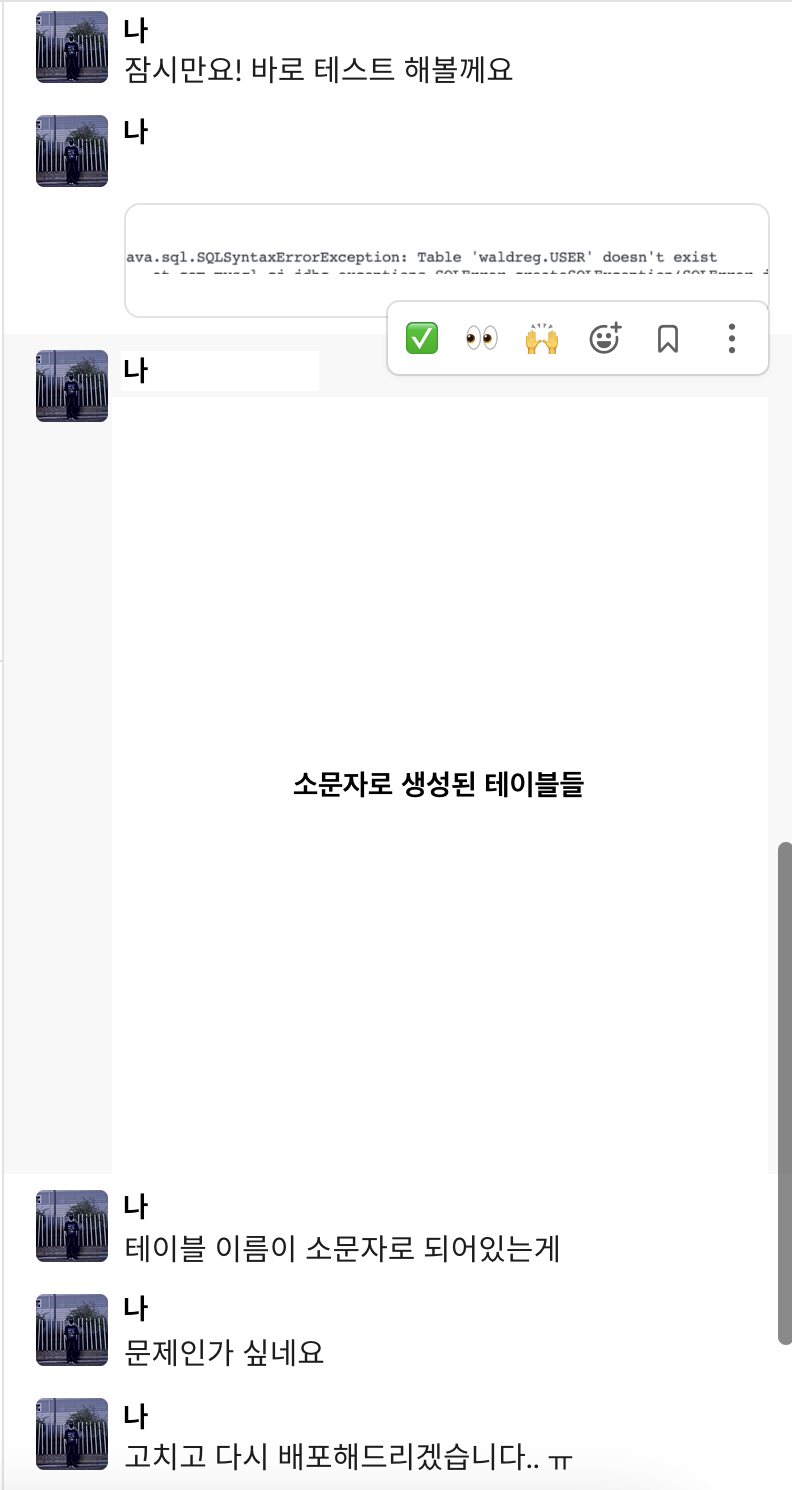
MySQL에서 테이블 이름이 소문자로 생성되었는데, Native Query에서는 테이블 이름이 대문자로 표현되어 있는것이 문제였다.
(아니, 데이터 표현 객체에서는 테이블 이름을 대문자로 생성하게 했는데 도대체 왜?)
여하튼 우리는 hibernate 설정에 테이블을 만들때 테이블 이름을 대문자로 생성하게끔 설정을 해주었고... 사소한 문제가 발생했고 쉽게 해결되었다고 생각한채 0.5.1 버전을 배포한다.

과연 모든 문제가 해결되었을까?
...🥲
모든 문제는 mysql에서 지원하는 SQL과 h2에서 지원하는 SQL이 달랐기 때문에 발생했는데, 예를들어, Mysql은 bool 타입으로 1,0을 반환하는 반면, h2는 true, false를 반환했다.
무엇이 문제였는가?
우리는 jpql의 이점중 하나인 "DBMS마다 다른 SQL을 추상화" 를 간과했고, 모든 문제는 여기서 발생했다.
또한, 인수테스트에서 운영환경이 아닌 h2로 테스트를 진행했고, 이는 실제 운영 DBMS를 연결했을때 발생 할 오류를 잡아주지 못했다.
다시, 앞선 가정으로 돌아가보자.
1. h2를 사용해서 모든 테스트가 통과하면 실제 운영환경에서 사용할 데이터베이스를 사용해도 모든 테스트가 통과할것이다.
2. 스프링 데이터 jpa가 제공하는 sql 방언을 사용하면, 구체적인 데이터베이스를 언제든지 바꿀 수 있다.
이 가정이 맞기 위해선, Native Query가 아닌 Jpql로 SQL을 추상화 시켜줘야 했다.
즉, 추상화를 거치지 않고 Native Query를 직접 사용함으로 써 우리의 repository 모듈은 특정 DBMS (h2, Mysql)에 대해 의존적으로 변한것이였다..!
해결
문제상황을 분석해보니 우리가 정한 페이징 정책이 잘못된 것 이였다.
따라서, 우리는 고수준의 정책부터 세부사항인 컨트롤러, DB, url을 모두 변경해야했는데, 이는 프론트와 백 양쪽의 변경을 의미했기 때문에, 변경에 들어가는 비용이 결코 적지 않았다.
이 방법밖에 없을까..?
1. 모든 문제는 조회 메소드에서만 발생한다.
2. 현재상황에서 우회할 방법이 존재한다. 심지어 그 방법은 Nativey Query가 아닌 EntityManager에 jpql을 날리는 방법으로 가능하다.
따라서, 우리는 페이징 정책(나름 쓸만하다고 생각한다..아마도)을 변경하는것을 포기하고 조회 메소드에 한해서 EntityManager에 jpql로 쿼리를 날리는 방법을 채택했다.
(Spring data jpa를 사용하지않고 EntityManager에 jpql로 쿼리를 날리면 해결할 수 있었다.)
또한, 이 기회에 CQRS 패턴을 적용해 보는것도 나쁘지 않을것 같다.
결론
항상 눈에 보이지 않는 추상화를 조심해야 한다고 생각하고 조심하려고 노력하지만, 지키기가 쉽지 않은것 같다.
'회고' 카테고리의 다른 글
| [회고] 꾸준히 유지되는 사이드가 되기 위해서 (6) | 2024.10.13 |
|---|---|
| [회고] 주니어 개발자 되기 까지 aka. 삶의지도 (0) | 2024.09.21 |
| [회고] 디프만 13기를 마치며 - 서버 개발자 (2) | 2023.07.26 |
| [끄적끄적] Effective software testing 적용기 (0) | 2023.06.22 |



