TL;DR
이것외에도, 트랜잭션 안에서 retry를 할 경우 여러가지 문제가 발생할 수 있는데요.
저와 마찬가지로 jitter 방식의 retry정책을 구현할 경우, 해당 스레드는 커넥션을 든채 jitter 시간만큼 대기하게됩니다. 즉, 동시성 처리에 안좋은 영향을 끼칠 수 있어요.
(이것은 Webflux와 같은 reactive 프로그래밍에서도 마찬가지입니다. 비동기환경에서도 context에 커넥션이 묶인채로 jitter시간동안 대기하게되어요.)
반면, retry로직을 로컬 트랜잭션 밖으로 빼줄경우, 해당 이벤트가 jitter 만큼 대기할때, 다른 이벤트가 커넥션을 재사용할 수 있다는 이점이 있습니다.
또한, MySQL InnoDB의 Isolation level을 REPEATABLE READ 이상으로 설정할경우, MVCC 를 이용해서, 한 트랜잭션안에서는 항상 같은 데이터를 반환합니다. 즉, 낙관적락을 사용하면서, retry가 트랜잭션 안에 있을경우 버전이 맞지 않아 무한반복하게 되어요. 또한, 비관적락의 경우 락을 획득해도 갱신손실의 문제가 발생할 수 있으니 주의해야합니다.
환경
spring-r2dbc:6.0.10
io.asyncer:r2dbc-mysql:1.0.4
webflux:6.0.10
mysql:8.0.33
문제상황
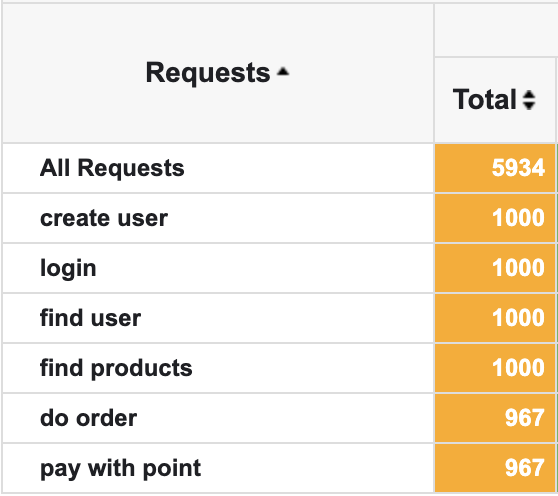
최근 진행중인 프로젝트에서 DB max conneciton pool size 만큼만 데이터가 삽입되고, 이 후의 데이터는 더 이상 insert 되지 않은채 Connection Timeout 이 반환되는 버그가 발생했습니다.
예시로, max connection pool size을 40으로 설정하고 부하테스트를 돌려보면, 아래 사진과 같이 "do order" 요청부터는 42개의 요청만 들어간걸 볼 수 있었어요.

문제의 코드와 해결
요청이 들어가지 않는 요인은 여러가지가 있을 수 있었는데요.
저의 경우는 아래와 같은 이유로 DB 커넥션쪽을 의심하며 디버깅을 시작했고, 서버 스펙을 변경하며 지속적으로 테스트한 결과 다음과 같은 에러를 얻을 수 있었습니다.
1. 모니터링결과 peek thread수와 cpu 사용량이 높지 않았고 webflux 환경이여서 클라 <-> 서버 사이의 문제는 아닐거라고 추측
2. 사용하고있는 분산트랜잭션 라이브러리의 트랜잭션 이벤트는 잘 수신하고 있었기 때문에, 컴퓨팅 리소스 문제는 아니라고 추측
3. 1번과 2번에도 불구하고 DB까지 도달한 요청이 42개밖에 안되기 때문에 서버 <-> DB 사이의 문제라고 추측

update중에 Lock을 얻지 못해 Timeout이 뜨고있던 것 이었어요.
에러정보를 바탕으로 코드를 추적해본결과, 아래 사진의 문제의 코드를 찾을 수 있었습니다.
Product 도메인에서는 낙관적락을 사용하고 있었고 그 때문에, OptimisiticLockingFailureException이 발생할 경우 성공할때까지 시도하는 로직이 존재했습니다.

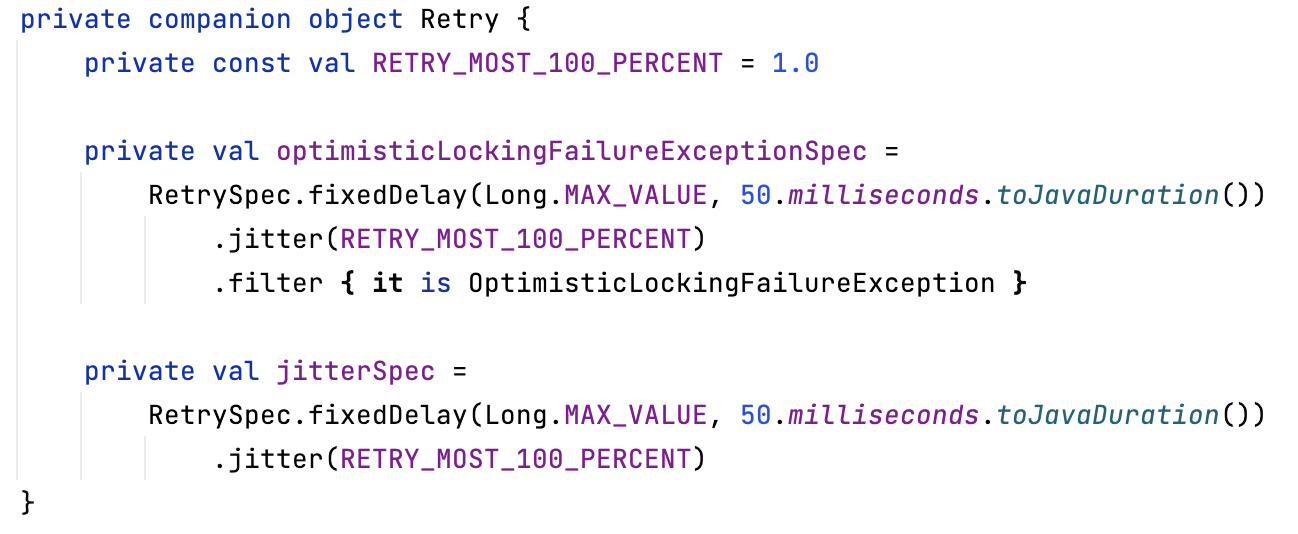
이때, retry 로직이 @Transactional 안에 있는게 문제라고 생각했고, 아래코드와 같이 retry를 @Transactional 밖으로 빼고 다시 테스트를 진행해봤습니다.
(아래 코드의 joinTransaction, commitOnSuccess, rollbackOnError는 로컬트랜잭션이 아닌 분산트랜잭션쪽이라서 @Transactional과는 무관해요)

1분동안 1000개의 요청을 보내본 결과, 이번에는 모든 요청이 성공적으로 들어가는걸 볼 수 있었습니다.
왜 이런 버그가 발생한걸까요?
@Transactional과 retry
저는 처음에, "retry때마다 새로운 커넥션을 얻어오기 때문에, 커넥션 수가 급격히 줄어들고 데드락이 발생한거 아냐?" 라고 생각했었는데요. 제가 작성한 글 How to maintain Transaction in Spring data R2DBC 을 읽어보면 아시겠지만, spring data r2dbc의 선언적 트랜잭션은 DB 커넥션을 reactor의 context로 관리합니다. 또한, 상위 퍼블리셔의 context는 이너 퍼블리셔에서 재사용하기 때문에, 이것은 원인이 아니었어요.
데드락의 원인은 생각보다 간단했는데요.
아래 코드를 보시면, Long.MAX_VALUE 만큼 재실행을 하는데, 이때, jitter 방식으로 50-100 milliseconds 만큼 대기하다가 재실행을 합니다. 하지만, 대기 시간이 짧아서 많은 요청들이 (거의)동시에 재실행하게 되고 동시에 실행한 트랜잭션들이 다시한번 OptimisitcLockingFailureException 을 던지게 되죠. 이 상황이 무한반복 되는것이었어요.
이것외에도, 트랜잭션 안에서 retry를 할 경우 여러가지 문제가 발생할 수 있는데요.
저와 마찬가지로 jitter 방식의 retry정책을 구현할 경우, 해당 스레드는 커넥션을 든채 jitter 시간만큼 대기하게됩니다. 즉, 동시성 처리에 안좋은 영향을 끼칠 수 있어요.
(이것은 Webflux와 같은 reactive 프로그래밍에서도 마찬가지입니다. 비동기환경에서도 context에 커넥션이 묶인채로 jitter시간동안 대기하게되어요.)
반면, retry로직을 로컬 트랜잭션 밖으로 빼줄경우, 해당 이벤트가 jitter 만큼 대기할때, 다른 이벤트가 커넥션을 재사용할 수 있다는 이점이 있습니다.
또한, MySQL InnoDB의 Isolation level을 REPEATABLE READ 이상으로 설정할경우, MVCC 를 이용해서, 한 트랜잭션안에서는 항상 같은 데이터를 반환합니다. 즉, retry가 트랜잭션 안에 있을경우, 무한반복하게 되어요.
마치며
별 생각없이 @Transactional 안에 retry 정책을 넣었고, 부하발생시 커넥션이 부족해지는 에러가 발생했습니다. 이 글을 읽는 분들은 저와같은 실수를 하지 않기를 바라며, 글을 마치겠습니다.
긴 글 읽어주셔서 감사합니다 :)
모든 코드는 아래 링크에서 확인할 수 있습니다.
https://github.com/rooftop-MSA
rooftop msa
rooftop msa has 13 repositories available. Follow their code on GitHub.
github.com
'끄적끄적' 카테고리의 다른 글
| [끄적끄적] 주문 Saga Isolation 부족 해결하기 (1) | 2024.05.02 |
|---|---|
| [끄적끄적] 결제 중복 롤백 방지하기 (3) | 2024.03.31 |
| [끄적끄적] ProtocolBuffer로 API 문서 작성기 (0) | 2024.01.13 |
| [끄적끄적] E2E(API) 테스트 자동화 도입기 (0) | 2023.10.18 |
| [Sonarqube] Sonarqube 설치 + PR decoration 하기 (0) | 2023.05.07 |



