재가공하고 내용을 추가한 글 을 미디엄 에서 읽어 보실 수 있습니다.
https://medium.com/@develxb/how-to-relation-entity-on-r2dbc-72e7dd4acdb2
기술 스택
r2dbc의 경우 드라이버에 따라 동작방식이 다른경우가 있습니다. 연관관계의 경우 spring 추상화 기술을 통해서 동작하기 때문에 이런 문제가 발생하지는 않을것 같지만, 같은 데이터베이스를 사용하더라도 다른 드라이버를 사용하는 경우가 있어서.. 시작전에 이 포스팅에서 사용한 기술스택과 버전을 정의하도록 하겠습니다.
spring data r2dbc version: 3.1.1
JDK version: 21
Database: H2(테스트), MySQL(운영)
R2DBC Driver: io.r2dbc:r2dbc-h2(테스트) io.asyncer:r2dbc-mysql(운영)
문제
Webflux를 사용함에따라, R2DBC를 사용하게 되었는데 R2DBC는 ORM이 아니라, 연관관계를 처리해주지 않습니다.
따라서, (OneToMany 혹은 ManyToOne 과 같은) 연관관계를 처리하려면 서비스 로직에서 Repository를 여러번 호출하고 조합해줘야 했는데요, 이렇게 하면 구현은 쉬워지지만,서비스 로직이 데이터베이스 연결기술(R2DBC) 에 강하게 묶이는 문제가 있습니다.
R2DBC의 연관관계 매핑 기술
아래 사진을 보면, R2DBC에서는 단일테이블에 한해서 매핑을 지원하지만, 여러개의 테이블에 대해서 연관관계 매핑을 지원하지는 않습니다.
즉, 연관관계를 처리하려면 추가적인 구현이 필요합니다.

spring data r2dbc를 사용하고 있다면, 다양한 방법으로 연관관계를 구현할 수 있습니다.
저장 구현
저희가 구현하고자 하는 도메인은 아래 사진과 같습니다.
Identity가 Role을 List로 들고있는 구조입니다. 즉, Jpa에서는 @OneToMany 관계이며, One은 Identity, Many는 Role입니다.
이때, 구현의 최종 목표는 아래와 같습니다.
1. service에서 Identity만 저장해도 연관된 Role이 같이 저장되어야 합니다.
2. Identity를 조회하면 연관된 Role이 함께 조회되어야 합니다.
(따라서, RoleIdentityRepository는 만들필요가 없고, IdentityRepository만 만들면 됩니다.)
spring data r2dbc의 Repository는 커스텀 인터페이스를 상속받고 구현채를 등록하면 해당 구현채의 기능을 사용하는데요 이 방식으로 구현하기 위해서 아래와 같이 IdentityRepository에서 IdentityCustomRepository를 상속받아 줬습니다.
IdentityCustomRepository의 모습은 아래와 같습니다.
이제, IdentityCustomRepository를 구현한 클래스를 등록해주면 되는데요, 이때 주의할점은 구현채의 이름은 반드시 도메인 이름 + RepositoryImpl 처럼 되어야 합니다.
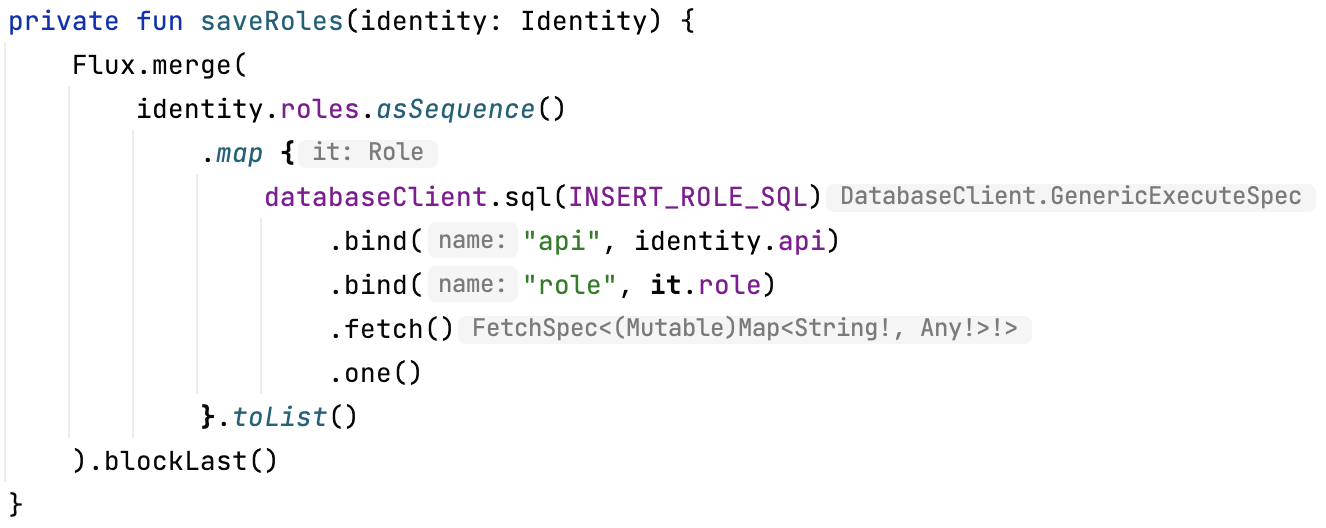
따라서, IdentityRepositoryImpl 구현채를 만들고 saveIdentity 메소드를 먼저 구현해보겠습니다.
saveIdentity 메소드를 보면 databaseClient에게 SQL을 전달하고, 파라미터를 바인딩 해주는걸 볼 수 있습니다.
databaseClient는 spring data r2dbc 에서 제공하는 reactive db client의 추상화 기술입니다. databaseClient를 통해서 저희는 드라이버에 상관없이 요청을 reactive하게 할 수 있습니다.

실제로 동작하는지 확인하기 위해서 테스트를 해보겠습니다.
아래 사진은 테스트 코드입니다.


이렇게 간단하게 구현할 수 있지만.....
정말 중요한것은, r2dbc가 reactive하게 동작한다는 점 입니다. 이것을 모르고 구현하게 되면 r2dbc가 주는 비동기 동작의 이점을 누릴수 없을 가능성이 높습니다.
1. reactor 는 stream과 같이 lazy하게 동작합니다. 만들때 평가가 실행되는것이 아니고, subscribe 시점에 평가가 시작됩니다.
예를들어, 아래 로직의 출력결과는 어떻게 될까요?

reactor에 익숙하시다면, 쉽게 예측이 가능했을겁니다. 우선, 1이 출력되고 그 다음에 SQL이 로그로 찍힙니다.
즉, 실제로 호출전까지 SQL은 수행되지 않는다는 점 입니다.
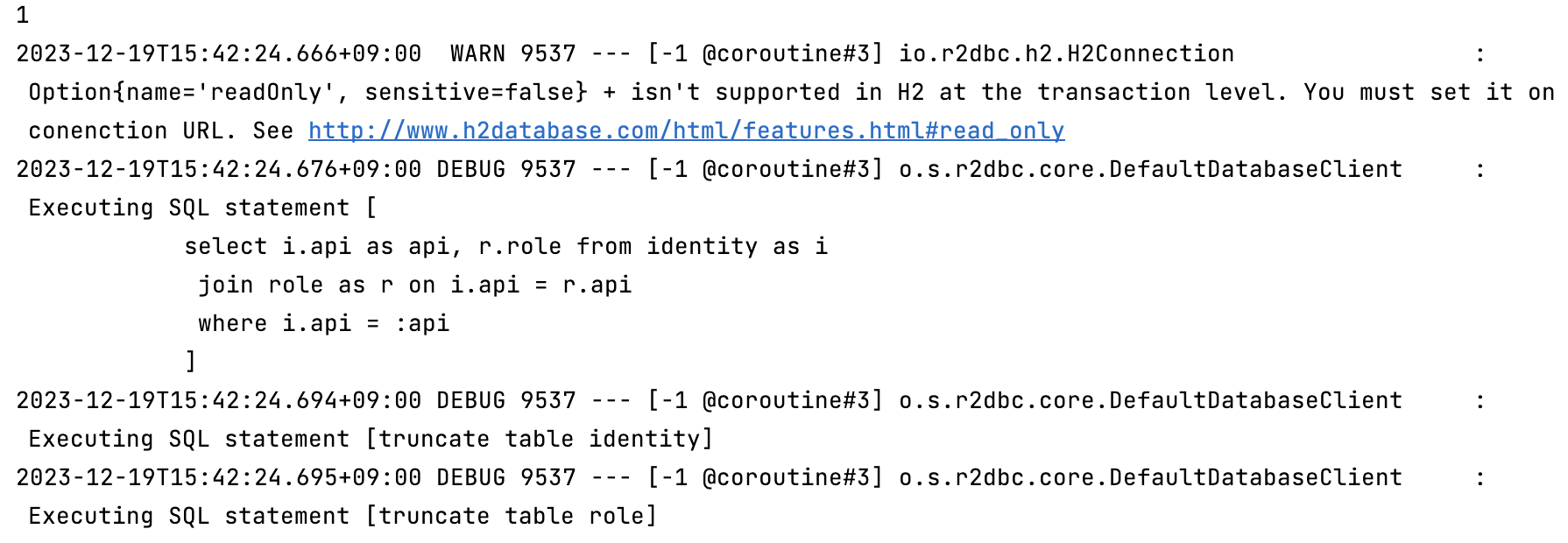
2. 호출을 절대 block해서는 안되며, 체이닝 시켜서 응답해야 합니다.
예를들어 보겠습니다.
위의 private fun saveRoles 메소드를 아래 코드와 같이 block() (혹은 subscribe) 시킨다면 어떻게 동작할까요?
saveRoles를 호출하는 코드는 이미 lazy 하게 평가되기 때문에, 메소드 호출시점에 SQL이 수행되지는 않겠지만 언젠가 saveRoles메소드를 호출할 때 스레드는 블로킹 됩니다. (block이 아닌 subscribe를 하더라도 마찬가지입니다.) 왜냐하면.. saveRoles가 응답될때까지 호출자는 기다려야하기 때문입니다.
물론, 아래 코드는 저희가 의도한대로 identity를 저장했을때, 연관된 Role도 함께 저장하기는 합니다.
조회 구현
위의 주의할 점을 상기하면서 findByApi 메소드를 구현해보겠습니다.
마찬가지로 databaseClient를 사용하며 이때, databaseClient는 응답으로 Flux<Map<String, Any>> 를 반환합니다.
Flux의 element는 DB의 row를 뜻하며, Map은 row의 column을 뜻합니다.
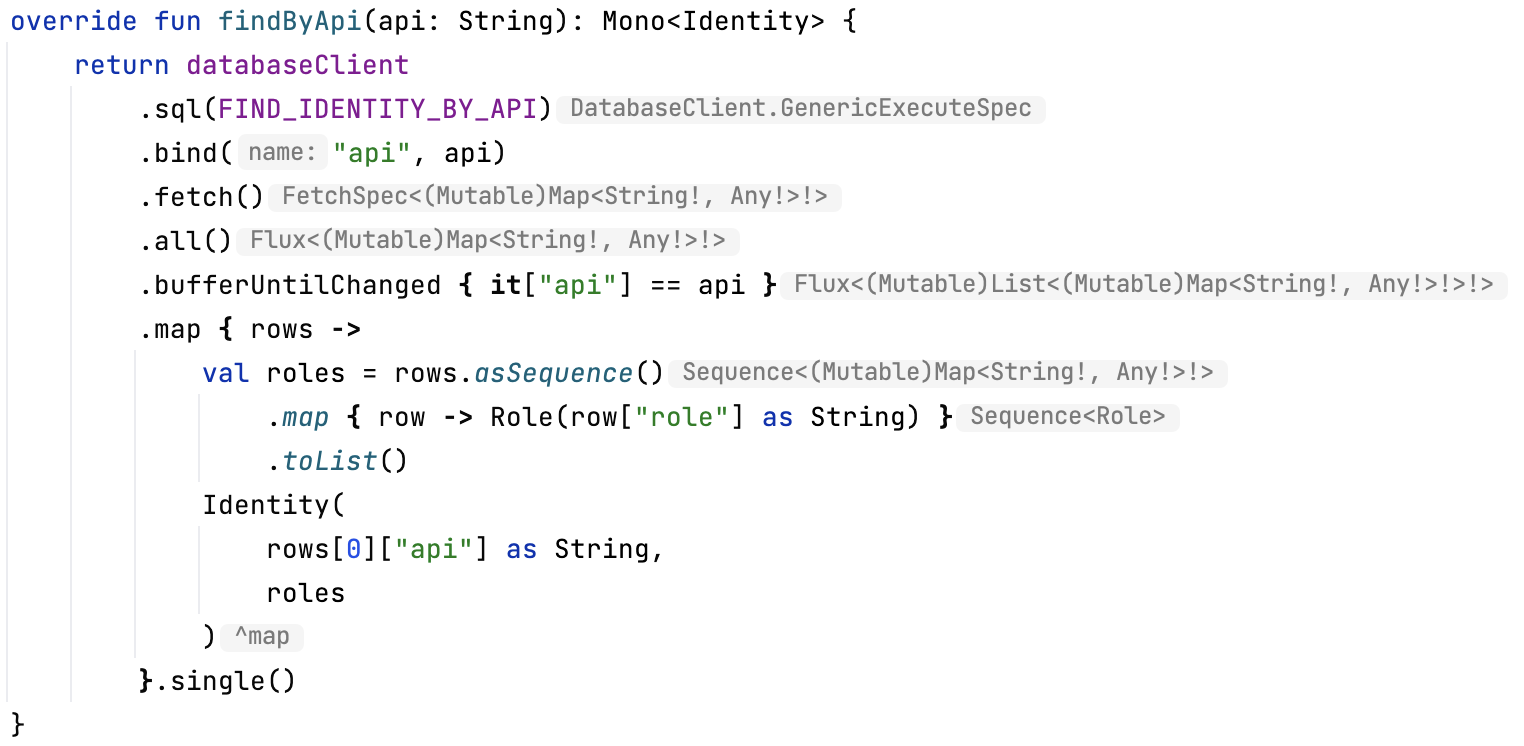

조회때 주의할점은, oneToMany의 경우, bufferUntilChanged로 다른 값이 나올때까지 버퍼링(하나로 묶어)해주어야 합니다.
사실 위 코드의 경우 크게 필요하지는 않고 포스팅 목적으로 추가한건데요, 예를 들어.. 아래와 같은 SQL을 작성한다고 가정해보겠습니다. where절이 빠졌는데요 이때는, api가 같은것들이 하나로 묶여서 join됩니다.
select i.api as api, r.role from identity as i join role as r on i.api = r.api
하지만, 조회된 결과의 순서는 아래 표와 같이 하나로 묶여있지 않을 수 있습니다.
(정확하지는 않지만 Reactive하게 동작하기 때문인것 같습니다. 테스트 결과 DB상에서는 하나로 묶여나오지만, WAS에서는 순서가 다른경우가 발견되네요..)
| api | r.role |
| "GET /healths" | "CUSTOMER" |
| "POST /users" | "ADMIN" |
| "GET /healths" | "ADMIN" |
이 결과를 버퍼링해주지 않는다면, GET /healths에 대한 결과가 여러개 나올 수 있습니다.
다른 방법들
이번 포스팅에서는 R2DBC 연관관계에 대해서 알아보았습니다.
이것외에 아래 코드와 같이 Converter를 등록하는 방법도 있으며, Repository 인터페이스에 @Query 어노테이션을 이용한 방법도 존재합니다.

모든 코드는 아래 링크에서 확인하실 수 있습니다.
(글을 작성하는 12.19 시점에는 아직 main에 merge되지 않았습니다.)
https://github.com/rooftop-MSA/identity-server
GitHub - rooftop-MSA/identity-server: 👾 Accounts and Authentication server
👾 Accounts and Authentication server. Contribute to rooftop-MSA/identity-server development by creating an account on GitHub.
github.com
'Reactive stack' 카테고리의 다른 글
| [Reactive stack] Reactor pool로 Lettuce Connection 조절하기 (0) | 2024.03.16 |
|---|---|
| [Reactive Stack] webflux, R2DBC 환경에서 Event 사용하기 (0) | 2024.01.16 |
| [Reactive stack] MVC에서 WebTestClient로 테스트 하기 (0) | 2024.01.02 |
| [Reactive stack] Spring data R2DBC 커넥션 유지 방법 (1) | 2023.11.30 |
| [Reactive stack] R2DBC with mysql 삽질기 (1) | 2023.11.01 |



