최근에 Redis HA 를 공부하다가, 다음과 같은 의문이 들었습니다.
"sentinel구조에서 master 노드가 다운되었을때, failover 과정중 들어오는 데이터들은 어떻게 되지???"
검색을 해봐도 원하는 내용이 설명되어 있는 자료를 찾기 힘들어서 직접 테스트 해보기로 결심했습니다.
구성
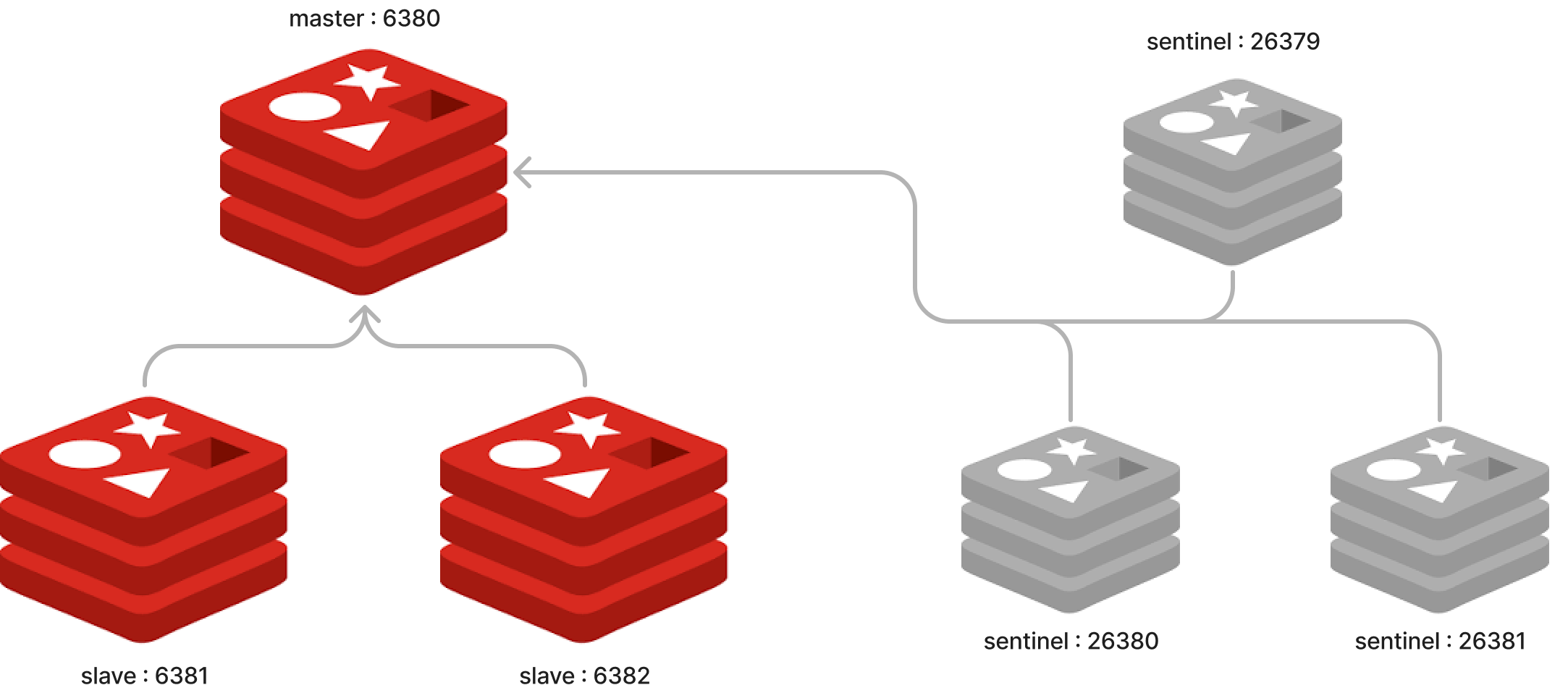
구성은 아래와 같습니다.
redis-server version : 7.2.1
lettuce core : 6.2.4
monitoring : redis-stat
아래 더보기를 여시면 sentinel 구성파일을 다운받을 수 있습니다. 혹시나 따라하실분은 아래 파일을 다운받아서 사용하시면 될것 같습니다.
처음에는 편하게 docker로 구성했는데, sentinel에서 master-node ip를 응답하는 과정에서 docker 내부 ip를 응답해줘서 설정이 힘들었습니다. 그래서 docker를 사용하지 않고 서버를 직접 띄웠습니다.
테스트 - master node가 죽었을때
테스트 언어로는 kotlin을 사용했으며, 0.1초에 한번씩 redis-server에 set 연산을 진행했습니다.
마지막에 redisTemplate.keys("*") 로 처리할경우, keys 명령임에도 scan 처럼 10개씩 조회를 해서 execute로 명령을 직접 실행해줬습니다.

테스트하기전에, redis-sentinel 구성이 잘 되었는지 확인해보겠습니다.
redis-stat은 docker로 띄워서 host가 host.docker.internal 입니다. 포트를 보면, 모두 잘 띄워졌고, 포트번호 6380 노드가 master, 6381, 6382노드가 slave로 구성되어 있습니다.

테스트를 시작하고, data를 set하는 중간에 master redis(포트번호 6380) 을 kill 해보겠습니다.
6380 redis는 죽고, 6382번 redis가 master node로 승격된 모습을 아래 사진을 통해 알 수 있습니다.

결과는 어떻게 될까요? 아래의 사진을 보면,
첫번째 테스트는 실패했고 999개가 저장되었습니다.
두번째 테스트는 성공했고 1000개가 전부 저장되었습니다.



왜 이런 결과가 발생했을까요?
첫번째 테스트와 두번째 테스트의 시나리오는 똑같습니다. 중간에 무작위 시간에 master-node를 정확히 1번 kill 했습니다.
Lettuce 구현을 사용할경우, master node와 커넥션이 끊어진다면 reconnect를 시도하고 connection이 끊어졌다고 판단되면, sentinel로 새롭게 받아온 정보로 reconnect를 진행합니다.
아래 log를 보면, 6380으로의 연결이 끊어졌을때, 6382 port로 재연결 된것을 볼 수 있습니다.

1번 테스트와 2번 테스트가 서로 다른 결과를 보여주는 이유는 데이터를 보내는 시점에 차이가 있습니다.
2번 테스트의 경우는 "데이터를 보내지 않는 동안" 재연결이 발생했기 때문에 데이터가 유실되지 않았습니다. 하지만, 1번 테스트는 "데이터를 보내는 중간"에 connection이 끊어지게 되었고 데이터가 유실되었습니다.
(세번째 테스트는 인위적으로 레디스를 막 껏다켰다 해서 발생한 상황이라... 실제 세계에서의 시나리오와 유사한지는 잘 모르겠고 실제로 이렇게 자주 failover가 발생한다면 메모리 증설이나 설정을 바꿔야할것 같습니다.)
세번째 테스트의 경우는 (redis log를 남기지 않았네요..) 정확한 이유를 유추하기는 힘들지만.. 아마 다음과 같은 이유로 발생했을것이라 추측됩니다.
1. 비동기로 sync가 진행되는 중에 master node가 강제로 다운됩니다.
2. 다운되었던 노드가 살아나고(이때, RDB 방식을 사용했는데, RDB에 데이터가 저장되기전에 노드가 다운되어서 데이터는 없습니다.) master node와 sync하는 과정에서 partial sync를 사용하지 못한채 full sync가 발생하게 됩니다.
3. 이 과정중에 다시 master node가 강제로 다운됩니다.
4. 데이터가 날라갑니다.
redis는 7.0.8 버전부터 full sync과정을 (master)memory to (slave)disk 방식으로 진행합니다. 자세한 과정은 아래 내용을 참고해주세요.
http://redisgate.kr/redis/server/repl_full_sync_mem_disk.php
Redis Full Sync Memory-to-Disk
repl_full_sync_memory_disk Redis Full Synchronization Memory-to-Disk Overview 이 문서는 Redis 버전 7.0.8을 기준으로 작성했습니다. 키 개수는 약 1천만개이고 메모리는 1Gb입니다. Overview 다음 3개 파라미터는 마스터
redisgate.kr
또한, Redis 연결로 Lettuce 구현채를 사용할경우, 별다른 설정이 없다면, 1분동안 재연결을 시도합니다. 이때 발생하는 예외는 아래와 같습니다.

만약, 스프링환경에서 RedisTemplate 추상화 기술을 사용한다면, 다음 Spring 예외로 감싸져서 응답됩니다.

결론
HA 환경을 구성하더라도 데이터는 유실될 수 있습니다. 따라서, 데이터 성격에 따라 적절한 예외처리를 해주는것이 좋아보입니다.
Redis는 slave와의 sync과정에서 COW (Copy On Write) 방식을 사용합니다. 즉, 프로세스를 fork하고 해당 프로세스에서 비동기적으로 데이터를 sync하는데, 이 과정에서 메모리를 예상보다 많이 사용할 수 있습니다. 또한, 오래 저장된 데이터를 lru 하는 과정에서 데이터 파편화가 크게 발생해서, 메모리를 생각보다 많이 사용할 수 있습니다. 따라서, rss 지표를 잘 보고 서버를 적당히 구성해주는것이 좋아보입니다.

실제 코드는 여기 에서 확인하실수 있습니다 :)
'Redis' 카테고리의 다른 글
| [Redis] Redis-stream 메모리 누수와 XGROUP의 동작원리 (0) | 2024.05.27 |
|---|---|
| [Redis] Cluster 환경에서 Transaction 에러 해결하기 (0) | 2023.10.11 |
| [Redis] Transaction으로 갱신손실 문제 해결하기 (0) | 2023.10.07 |


