성능 테스트가 아닌, 프로토콜 버퍼를 gradle에 적용하는 부분이 궁금하신분은 아래에 새롭게 작성한 아티클을 참고해주시면 감사하겠습니다. 이 게시글에 작성된 내용은 레거시가 많아 현재 gradle에는 적용되지 않을 수 있습니다.
https://dlwnsdud205.tistory.com/363
[끄적끄적] ProtocolBuffer로 API 문서 작성 후기
최근에, 강남언니 기술블로그에 기술된 글을 재미있게 본 적이 있습니다. 강남언니 블로그에서는, 프론트엔드와 백엔드 간의 api를 protocol buffer로 정의 하면서 아래와 같은 이점을 얻을 수 있었
dlwnsdud205.tistory.com
[grpc] 3. grpc의 기반기술 - Protocol Buffers
목차
1. https://dlwnsdud205.tistory.com/326 [grpc] 1. grpc의 기반기술 - RPC
2. https://dlwnsdud205.tistory.com/327 [grpc] 2. grpc의 기반기술 - HTTP/2.0
3. https://dlwnsdud205.tistory.com/328 [grpc] 3. grpc의 기반기술 - Protocol Buffers와 성능 테스트
4. https://dlwnsdud205.tistory.com/329 [grpc] 4. grpc - Java
grpc를 공부하기위해선 우선 grpc의 몇가지 기반 기술들을 알아야한다.
이번 포스팅에서는 grpc의 기반 기술 protocol buffer에 대해서 알아볼 것이다. 이 포스팅에는 grpc의 개요 와 자바에서의 사용예시를 적을 것 이며, protocol buffer 사용법은 내가 번역한 글을 읽도록 하자. 이 글을 읽기전에, 혹은 개요까지 읽은 후 아래 사용법을 숙지하고 다시 읽는것을 추천한다.
https://github.com/devxb/javaNote/tree/main/protocolBuffers
GitHub - devxb/javaNote: grpc, springboot, kafka 등등 공부장 with Java
grpc, springboot, kafka 등등 공부장 with Java. Contribute to devxb/javaNote development by creating an account on GitHub.
github.com
또한, 이 포스팅에 있는 모든 코드도 위 깃허브 링크에서 확인할 수 있다.
1. Protocol Buffers
protocol buffers는 언어와 플랫폼에 중립적인 구조화된 데이터를 직렬화 하는 기술이다. protocol Buffer를 이해할때, json을 떠올리면 쉬운데, json보다 더 작고 빠르며, .proto파일을 읽고 사용자 맞춤 언어(c++, java, python 등등) 바인딩을 생성해준다.
protocol buffers는 일종의 선언 언어(원문은 Defination language로 되어있음 하지만 한국어로 번역하면 선언 언어가 좀 더 어울리는 느낌임)로, protoc 컴파일러는 사용자가 .proto에 작성한 내용을 컴파일해 사용자 맞춤 언어를 만들어 준다.
2. Protocol Buffers의 이점과 단점
1. Protocol Buffers는 타입과 구조화된 데이터를 매우 적은 megabytes로 직렬화 하는데 이 직렬화된 데이터는 일시적인 네트워크 환경과 매우 긴 저장 환경에 모두 적합하다. 또한, Protocol Buffers는 기존의 데이터를 무효화 하거나 수정하지 않아도 확장 가능하다. 즉, Protocol Buffers는 데이터 저장과 네트워크 전송에 효과적인 직렬화 방식이라 할 수 있다.
2. Protocol Buffers는 언어와 플랫폼에 중립적이라 언어, 플랫폼에 중립적인 방식으로 type할때 이상적인 방법이다.
3. Protocol Buffers는 많은 프로그래밍 언어(C++, C#, Java, Pyhon, Ruby ...)를 지원하며, class 자동생성을 통한 최적화된 기능을 제공한다.
반면, protocol buffer의 단점은 아래와 같다.
1. 큰 데이터를 전송할때. protocol buffer는 메시지 전체를 memory에 올려두는데 메시지가 거대하다면 직렬화된 데이터 복사본이 메시지 위로 올라가 메모리 사용량이 급증할 수 있다. 따라서 데이터의 크기가 적은 megabytes를 초과하거나 객체 그래프 보다 크다면, 다른 방법을 선택하는것이 좋다.
2. protocol buffer가 직렬화 될때, 같은 데이터라도 다양한 이진 기법으로 직렬화된다. 이 말은 데이터 전체를 파싱 하지 않는다면 동등성 비교를 할 수 없음을 의미한다.
3. Protocol Buffer 사용법
번역본 : https://github.com/devxb/javaNote/tree/main/protocolBuffers
GitHub - devxb/javaNote: grpc, springboot, kafka 등등 공부장 with Java
grpc, springboot, kafka 등등 공부장 with Java. Contribute to devxb/javaNote development by creating an account on GitHub.
github.com
원문 : https://developers.google.com/protocol-buffers/docs/proto
Language Guide | Protocol Buffers | Google Developers
Language Guide This guide describes how to use the protocol buffer language to structure your protocol buffer data, including .proto file syntax and how to generate data access classes from your .proto files. It covers the proto2 version of the protocol bu
developers.google.com
4. 자바에서 Protocol Buffer 사용해보기 (proto3)
이제, protocol buffers를 자바에서 테스트해 보도록 하자. 실습? 내용은 다음 링크를 참조했다.
https://developers.google.com/protocol-buffers/docs/javatutorial
Protocol Buffer Basics: Java | Protocol Buffers | Google Developers
Protocol Buffer Basics: Java This tutorial provides a basic Java programmer's introduction to working with protocol buffers. By walking through creating a simple example application, it shows you how to Define message formats in a .proto file. Use the prot
developers.google.com
위 링크를 들어가보면, 링크는 proto2버전을 기준으로 실습을 진행하는데, 나는 proto3버전으로 변경해 진행했다. google에 따르면 grpc를 사용하려고 하는 경우, proto3가 proto2보다 추천된다고 한다. 이 포스팅의 최종 목적은 grpc이므로 proto3기준으로 테스트를 진행했다. 만약 proto2만 알고 proto3를 몰라도 실습 내용을 이해하는데 큰 어려움은 없을것이다.
테스트 환경
jdk 18.0.2
protobuf:3.21.5 (포스팅 기준 최신버전)
junit 5.8.1
의존성을 추가하기 쉽도록 gradle기반 자바 프로젝트를 하나 만들어 준 후, build.gradle에 다음 의존성을 추가한다. (protoc컴파일러에 의해 생성된 객체가 아래 의존성을 필요로 한다.)
implementation 'com.google.protobuf:protobuf-java-util:3.21.5'만약 버전이 안맞아 실행이 안된다면, 아래 링크로 들어가 자신에게 맞는 버전을 찾거나 최신버전을 기준으로 의존성을 업데이트 해주도록 하자. 다만 자신이 사용하고자 하는 버전이 proto2라면, 3.xx.x버전이 아닌, 2.xx.x버전을 사용해야 한다. (가장 앞의 숫자가 proto버전을 의미한다.)
https://search.maven.org/artifact/com.google.protobuf/protobuf-java-util/3.21.5/bundle
Maven Central Repository Search
search.maven.org
최종 적으로 의존성은 다음과 같이 추가가 되어있어야 한다.
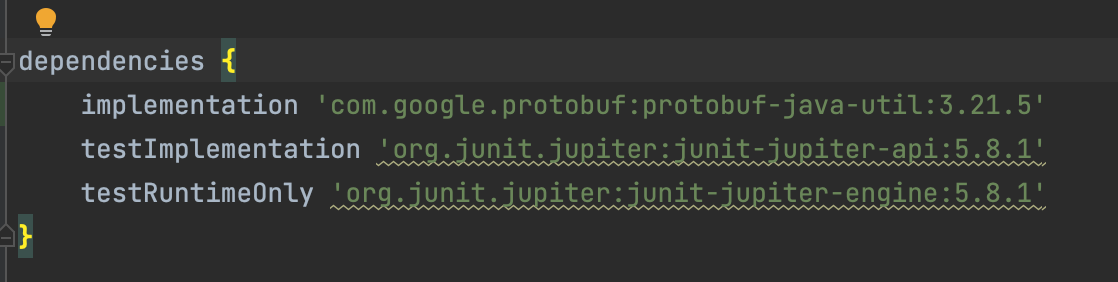
이제, 테스트에 사용할 .proto 파일을 작성하자.
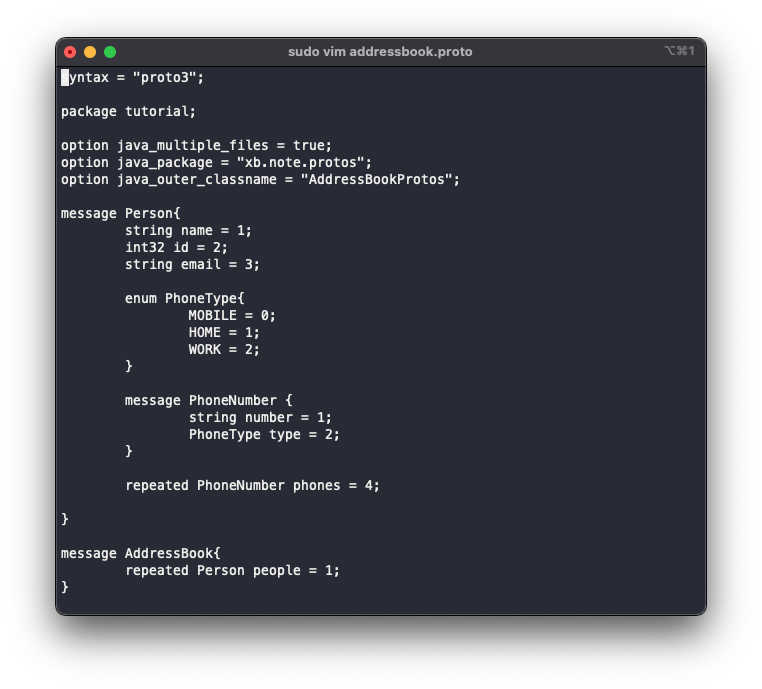
(위 내용들이 이해가 안된다면 번역본 혹은 원문을 읽고 오도록 하자)
위 내용들로 예상컨데, Person이라는 객체가 생성될것 이고 Person 객체는 name, id, email, phones를 필드로 갖고있으며, phones는 배열 형태가 될 것임을 알 수 있다. 또한, 내부 객체로 PhoneNumber와 열거형으로 PhoneType을 갖고있을 것이다.
추가로 AddressBook이름의 객체가 생성되며 AddressBook객체는 Person타입의 배열 필드를 하나 갖고있을것이다.
실제로 위 파일을 컴파일 후 테스트 해보도록하자. protoc 컴파일러를 이용해 위 파일을 java코드로 컴파일하자
protoc --java_out=/Users/devxb/develop/javaNote/protocolBuffers/protocolBuffers/src/main/java/ addressbook.proto--java_out에는 컴파일된 java파일이 저장될 이름을 적어야한다. 주의할것이 --java_out옵션 + 파일에 있는 java_package경로가 추가되어 폴더가 생성된다. 따라서 java_package는 전체 경로에서 제거해줘야한다.
컴파일이 성공적으로 완료되었다면, 지정한 경로에 인터페이스와 클래스가 생성되었을 것이다. 이제, 작은 테스트 코드를 만들어서 예상한 구조대로 생성되었는지 테스트 해보도록하자.
전체 소스코드
package xb.note.protos;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
public class ProtoTest {
@Test
public void buildProtoFileTest(){
// given
Person xb = buildXb();
// then
Assertions.assertTrue(isWho(buildXb(), xb));
}
@Test
public void buildProtoFileFailTest(){
// given
Person xb = buildXb();
// then
Assertions.assertFalse(isWho(buildDev(), xb));
}
private Person buildXb(){
return Person.newBuilder()
.setName("xb")
.setId(1)
.setEmail("develxb@gmail.com")
.addPhones(Person.PhoneNumber.newBuilder()
.setNumber("1234-5678")
.setType(Person.PhoneType.MOBILE))
.build();
}
private Person buildDev(){
return Person.newBuilder()
.setName("dev")
.setId(2)
.setEmail("dev@gmail.com")
.addPhones(Person.PhoneNumber.newBuilder()
.setNumber("8765-4321")
.setType(Person.PhoneType.WORK))
.build();
}
private boolean isWho(Person expected, Person actual){
return expected.equals(actual);
}
}성공적으로 테스트가 완료되며, 생성된 구조도 예상과 같음(.proto파일의 구조)을 알 수 있다.
이제, protocol buffer의 자랑? 인 직렬화를 진행해보자. 직렬화 같은 경우는 다음 메서드 들을 제공하는데,
byte[] toByteArray();
void writeTo(OutputStream output);
그냥 직렬화만 하는것은 재미가 없으므로, Person을 직렬화 했을때와 하지 않았을때의 크기 차이를 비교해볼것이다. 다만, 자바에서는 객체의 정확한 크기를 측정하기가 어려우므로 직렬화된 데이터와 직렬화 되지않은 데이터의 크기를 '상대적'으로 비교할 것이다.
마찬가지로 간단한 테스트를 작성해보자.
이번에 작성할 테스트는 직렬화된 데이터를 직렬화되지않은 데이터보다더 많이 저장할 수 있는지 여부이다.
(노트북이 굉장히 뜨거워지니 따라하지는 말자)
private int countNoneSerializedPerson(){
int count = 0;
List<Person> personList = new ArrayList<>(); // gc 방지 용
try{
while(true){
Person xb = buildXb();
personList.add(xb);
count++;
}
}catch(OutOfMemoryError OOME){return count;}
}
private int countSerializedPerson(){
int count = 0;
List<byte[]> serializedPersonList = new ArrayList<>(); // gc 방지용
try{
while(true) {
Person xb = buildXb();
serializedPersonList.add(xb.toByteArray());
count++;
}
}catch(OutOfMemoryError OOME){ return count; }
}OutOfMemoryError가 날때까지 무한반복하고 생성하는 코드를 두개 만들었다. 이제 위 함수를 사용하는 테스트 코드를 만들고 실행해보자.
@Test
public void serializeTest(){
for(int i = 0; i < 100; i++){
int noneSeriallizedCount = countNoneSerializedPerson();
int serializedCount = countSerializedPerson();
Assertions.assertTrue(serializedCount > noneSeriallizedCount);
}
}100회 반복하며, 직렬화된 Person저장횟수가 직렬화 되지않은 Person저장횟수보다 커야한다.
(사실, 모든 컴퓨터에서 테스트가 정상적으로 동작할것이라는 보장은 없다. JVM과 GC버전에 따라 생성되는 객체의 크기, GC의 동작등이 모두 다르므로...)

오랜시간끝에 성공적으로 테스트가 끝났다.
다음으로 테스트할것은 직렬화된 데이터가 직렬화되지않은 데이터보다 몇개 더 저장 가능한가 이다. 기존의 serializeTest함수는 지우고(시간이 너무 오래걸리니) 새로운 테스트 함수를 작성한다.
@Test
public void serializeDiffNoneSerializeTest(){
long diff = 2;
for(int i = 0; i < 100; i++){
long noneSeriallizedCount = countNoneSerializedPerson();
long serializedCount = countSerializedPerson();
Assertions.assertTrue(serializedCount > noneSeriallizedCount + diff);
System.out.println("\n\n" + diff + "\n\n");
diff *= 2;
}
}이제 다시 테스트를 실행해보자. 이번에는 콘솔창에 찍히는 로그를 보기위해 --info 옵션을 줘서 실행할 것이다.

테스트결과 직렬화 데이터는 4194304 ~ 4194304*2 사이개 더 많이 저장된것을 알 수 있었다. 다만 직렬화된 데이터의 압축률은 객체에따라 다르므로 이 수치를 맹신하지는 말도록 하자.
또한, 테스트 결과 직렬화된 데이터와 직렬화 되지않은 데이터는 직렬화되지 않은 데이터 300만 직렬화된 데이터 870만으로 약 570만개 차이가 났다.
이렇게 grpc의 기반기술 rpc, HTTP/2, protocol buffers 포스팅이 모두 끝났다. 다음은 grpc포스팅으로 찾아오겠다.
이 포스팅에서 사용된 코드는 다음 링크에서 확인 가능하다.
GitHub - devxb/javaNote: grpc, springboot, kafka 등등 공부장 with Java
grpc, springboot, kafka 등등 공부장 with Java. Contribute to devxb/javaNote development by creating an account on GitHub.
github.com
'grpc' 카테고리의 다른 글
| [grpc] 4. grpc - Java (0) | 2022.09.08 |
|---|---|
| [grpc] 2. grpc의 기반기술 - HTTP/2.0 (1) | 2022.09.01 |
| [grpc] 1. grpc의 기반기술 - RPC (0) | 2022.09.01 |

